
Transcribe YouTube videos
Transcribe YouTube videos to get transcripts with timestamps using Whisper Large v3 from Open AI
This guide covers how to use, and optimise, Whisper Large v3 to extract text from the audio of YouTube videos. If you want to use this model straight away you can use a live version on our explore page here for free!
We will be covering the following:
- How to setup and install the necessary python dependencies
- Downloading YouTube videos
- Extracting Audio from a Video file
- Creating transcripts from an Audio file using
openai/whisper-large-v3from Huggingface.
We will be using the pipeline-ai library to wrap our code and try the model through a premade dashboard included in the library, but the code will work outside of this dependency as well and is easy to adapt.
All source code is available on our Github
https://github.com/mystic-ai/pipeline/tree/main/examples/audio-to-text/youtube-transcript
Setting up your environment
To begin you will need the following dependencies:
pipeline-ai==2.0.15
transformers==4.37.2
torch==2.2.0
accelerate==0.27.2
pytube==15.0.0
moviepy==1.0.3
and you will also need the following system dependencies:
sudo apt-get install -y ffmpeg
FFmpeg is necessary for the audio processing towards the end of this guide.
This can now be wrapped into the pipeline.yaml for your pipeline. Execute the following command in an empty directory to begin working with a fresh pipeline:
pipeline container init -n youtube-transcript
then in the pipeline.yaml paste in the following:
runtime:
container_commands:
- apt-get update
- apt-get install -y ffmpeg git
python:
version: "3.10"
requirements:
- pipeline-ai
- transformers==4.37.2
- torch==2.2.0
- accelerate==0.27.2
- pytube==15.0.0
- moviepy==1.0.3
cuda_version: "11.4"
accelerators: ["nvidia_l4"]
pipeline_graph: new_pipeline:my_new_pipeline
pipeline_name: youtube-transcript
description: null
readme: null
extras: {}
cluster: null
Downloading YouTube videos and getting the audio
To download YouTube videos we will be using the very simple pytube library and the YouTube object. This library supports downloading Videos in multiple formats, and other options, but we will reduce the complexity of this and only download the audio component of the video:
from pytube import YouTube
video_link = "PUT A LINK IN HERE"
audio_stream = YouTube(video_link).streams.filter(only_audio=True).first()
if audio_stream is None:
raise ValueError("Invalid video link")
audio_stream.download(filename="sample.mp4")
This will download the video locally to sample.mp4. Note that this is still in the mp4 format (video) so we need to perform one extra step to get a dedicated audio file out. This is where moviepy comes in:
from moviepy.editor import AudioFileClip
clip = AudioFileClip("sample.mp4")
clip.write_audiofile("sample.mp3")
Now we have our perfect audio file!
Now that we have the basic downloading/processing initial steps done we can put this code into our pipeline inference steps. In the new_pipeline.py python file in your directory you can update the code to the following:
from pytube import YouTube
from urllib.parse import urlparse
from moviepy.editor import AudioFileClip
from pipeline import Pipeline, Variable, entity, pipe
# Put your model inside of the below entity class
@entity
class MyModelClass:
@pipe(run_once=True, on_startup=True)
def load(self) -> None:
# Perform any operations needed to load your model here
print("Loading model...")
... # Model loading coming later
print("Model loaded!")
@pipe
def predict(self, video_link: str) -> dict:
print("Predicting...")
url = urlparse(video_link)
if url.netloc != "www.youtube.com":
raise ValueError("Invalid video link")
audio_stream = YouTube(video_link).streams.filter(only_audio=True).first()
if audio_stream is None:
raise ValueError("Invalid video link")
audio_stream.download(filename="sample.mp4")
clip = AudioFileClip("sample.mp4")
clip.write_audiofile("sample.mp3")
... # Inference coming later
print("Prediction complete!")
# print(result)
return result
with Pipeline() as builder:
input_var = Variable(
str,
description="Input video link",
title="Input video link",
)
my_model = MyModelClass()
my_model.load()
output_var = my_model.predict(input_var)
builder.output(output_var)
my_new_pipeline = builder.get_pipeline()
Extra validation
In the above snippet we use
urllibto validate the url and check that we are referencing YouTube correctly. This is highly recommended to avoid potential issues with URLs being incorrectly formatted and strange exceptions being raised.
Getting the transcript
This step is where the ML portion comes into play. Now that we have our audio file we can being to load the Whisper Large v3 model. We'll being doing this using transformers:
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
ml_pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
Performing inference is now very basic:
result = ml_pipe(
"sample.mp3",
return_timestamps=True,
)
'''
result = {
"text" : "this is the text ....",
"chunks" : [] # This is a list of the timestamps and texts
}
'''
We can wrap all of this code into our full pipeline script:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from pytube import YouTube
from urllib.parse import urlparse
from pipeline import Pipeline, Variable, entity, pipe
from moviepy.editor import AudioFileClip
# Put your model inside of the below entity class
@entity
class MyModelClass:
@pipe(run_once=True, on_startup=True)
def load(self) -> None:
# Perform any operations needed to load your model here
print("Loading model...")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
self.pipe = pipe
print("Model loaded!")
@pipe
def predict(self, video_link: str) -> dict:
print("Predicting...")
url = urlparse(video_link)
if url.netloc != "www.youtube.com":
raise ValueError("Invalid video link")
audio_stream = YouTube(video_link).streams.filter(only_audio=True).first()
if audio_stream is None:
raise ValueError("Invalid video link")
audio_stream.download(filename="sample.mp4")
clip = AudioFileClip("sample.mp4")
clip.write_audiofile("sample.mp3")
result = self.pipe(
"sample.mp3",
return_timestamps=True,
)
print("Prediction complete!")
# print(result)
return result
with Pipeline() as builder:
input_var = Variable(
str,
description="Input video link",
title="Input video link",
)
my_model = MyModelClass()
my_model.load()
output_var = my_model.predict(input_var)
builder.output(output_var)
my_new_pipeline = builder.get_pipeline()
Running the following commands will give you an interactive dashboard to try this locally:
pipeline container build
pipeline container up -d
And now navigate to your browser to see the following:
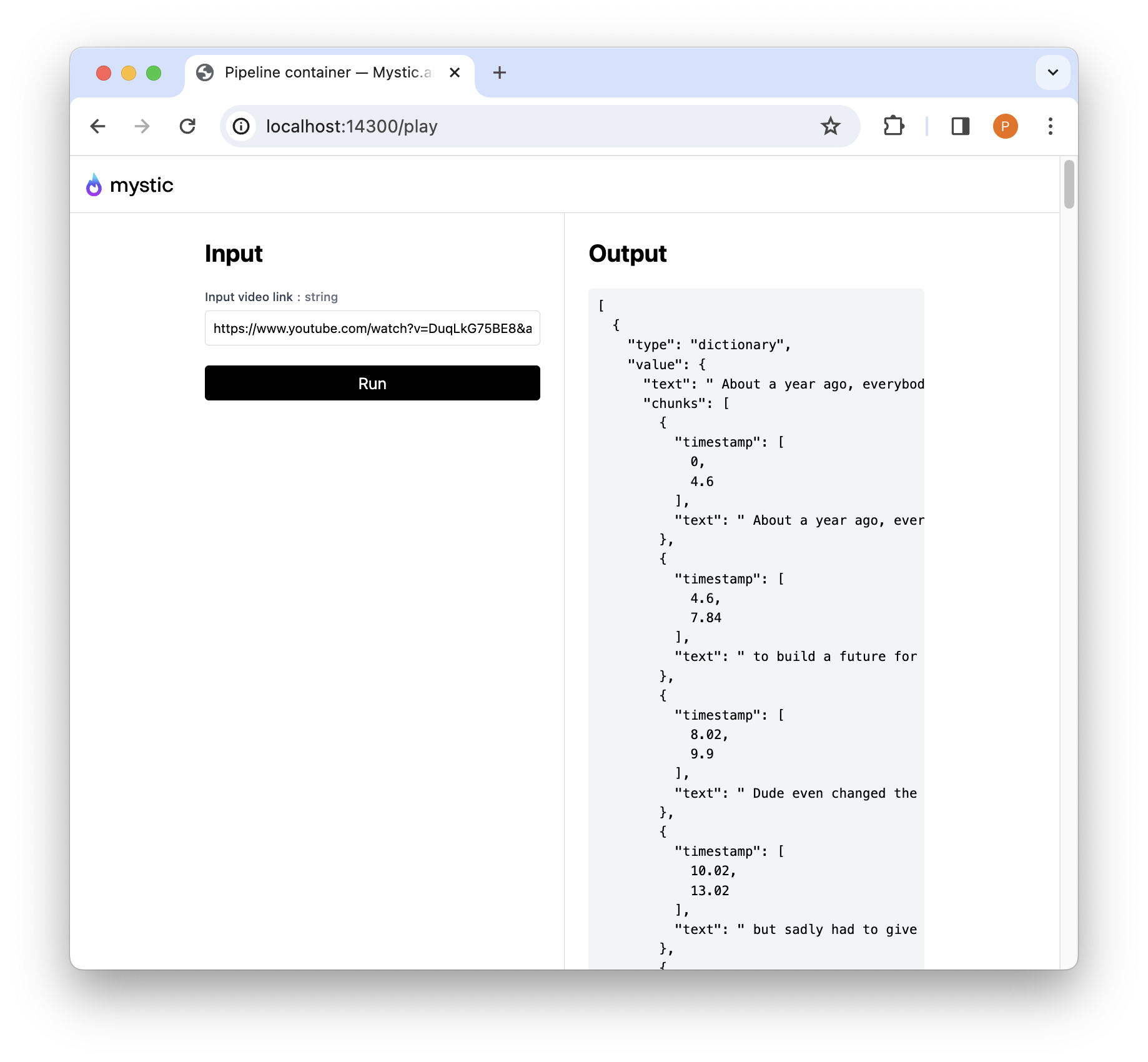
To deploy this privately on Mystic you can then run:
pipeline container push
Create an account to get serverless deployments
Create an account today at mystic.ai
Caching model weights to reduce cold start
To cache the model weights in the container so that they're not downloaded every time you will need to create a new file in the working directory called download_weights.py, and enter the following:
import torch
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
use_safetensors=True,
)
model.save_pretrained("./model_weights")
This will pull the weights to the local directory to be built directly into the container to reduce the cold start time. To use the weights you will need to point the model to the directory, and rebuild the container. After you've run the above script you will need to rebuild with pipeline container build, and then point transformers to that directory by editing the model load code to the following:
model = AutoModelForSpeechSeq2Seq.from_pretrained(
"./model_weights",
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
)
This will now look for the model locally instead of downloading it every time!
Updated over 2 years ago