
Gradio Llama 2 chatbot
A guide to running an ultra low cost Llama 2 chat bot in gradio with vLLM support.
Gradio demos provide a great way to validate model performance in more user facing ways than a standard CLI based tool. This guide shows how to run a customisable gradio based chatbot with a vLLM accelerated Llama 2. We will test all 7B, 13B and 70B variations to compare results.
Environment setup
Using an environment management system of your choice you will need to install the following dependencies:
pipeline-ai==1.0.1
gradio==3.43.2
Chatbot setup
import gradio as gr
from pipeline.cloud.pipelines import run_pipeline
llama2_7b_pipeline = "meta/llama2-7B-chat:latest"
llama2_13b_pipeline = "meta/llama2-13B-chat:latest"
llama2_70b_pipeline = "meta/llama2-70B-chat:latest"
target_model = llama2_13b_pipeline
generation_kwargs = dict(
max_new_tokens=200,
)
system_prompt = """You're a demo chat bot. Be kind, and precise in your answers!"""
with gr.Blocks() as demo:
system_prompt_box = gr.Textbox(
label="System Prompt",
placeholder=system_prompt,
)
chatbot = gr.Chatbot()
msg = gr.Textbox(
label="Message",
placeholder="Type your message here",
)
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
...
def system_update(new_prompt):
...
msg.submit(respond, [msg, chatbot], [msg, chatbot])
system_prompt_box.change(system_update, system_prompt_box)
demo.launch()
This won't perform full chat yet as we haven't populated the respond and system_update functions, but provides a starting place to build on.
Save this code to a local file, I use run.py in the guide, and run it with:
gradio run.py
This will launch the gradio server and provide a url for you to go to and view the bare bones bot. It should look like this:
Gradio demo bare bones
Making it run
Make sure to login
You need to authenticate your local system with Catalyst or your pcore deployment to run the following code:
pipeline cluster login catalyst YOUR_TOKEN -a
Now our next job is to populate the respond and system_update functions. For the respond function gradio injects the new message along with the chat history from the Chatbot object. The history is just an array of previous messages and responses so we need to format them appropriately given the standard chat syntax, find out more about that here.
def respond(message, chat_history):
_input = []
_input.append({"role": "system", "content": system_prompt})
for user_msg, bot_msg in chat_history:
_input.append({"role": "user", "content": user_msg})
_input.append({"role": "assistant", "content": bot_msg})
_input.append({"role": "user", "content": message})
output = run_pipeline(
target_model,
[_input],
generation_kwargs
)
new_message = output.result.result_array()[0][0]["content"]
chat_history.append((message, new_message))
return "", chat_history
This function starts by adding the system guide instruction and then appending all of the chat history to the final message array. Along with this the generation_kwargs are also passed in to the run_pipeline function as defined above. More information on the available kwargs is available in any of the model readmes, the main one to be conscious of is the max_new_tokens field, in this example it's set to 200 tokens.
Fortunately, the final function to fill in is very simple:
def system_update(new_prompt):
global system_prompt
system_prompt = new_prompt
This updates the default system prompt for you so that you can change the character of the bot on the fly without needing to reset the code.
Now that all functions are complete you can try the full chat bot out by running the same command as before:
gradio run.py
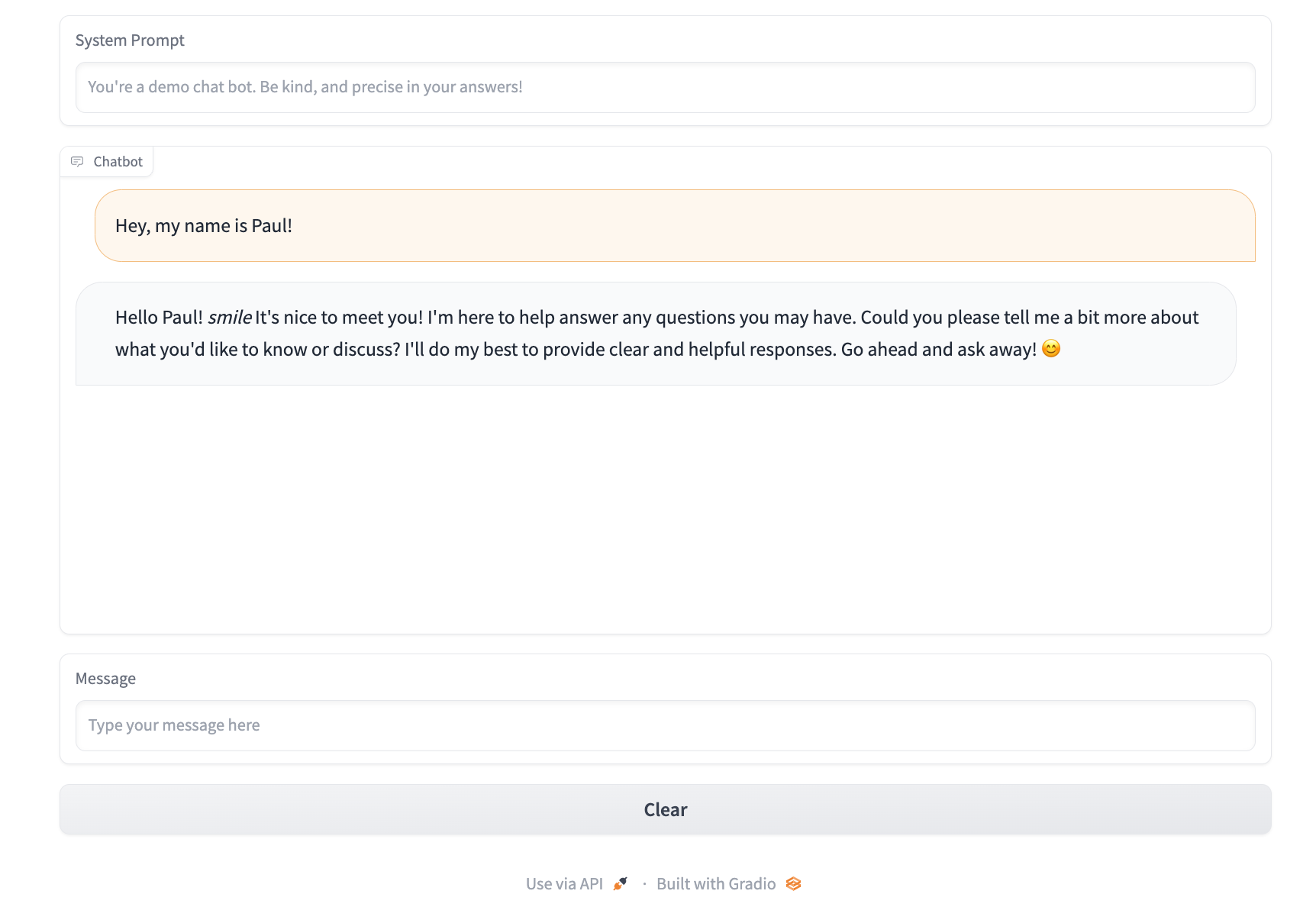
Model selection
To dynamically select which model you'd like to use, it's possible to add in an optional field called a Radio inside of the gradio context manager:
with gr.Blocks() as demo:
...
model_select = gr.Radio(choices=["7B", "13B", "70B"], label="Model Size")
def model_select_fn(model):
global target_model
if model == "7B":
target_model = llama2_7b_pipeline
elif model == "13B":
target_model = llama2_13b_pipeline
elif model == "70B":
target_model = llama2_70b_pipeline
...
model_select.change(model_select_fn, model_select)
This will provide a nice model selection box as shown below:
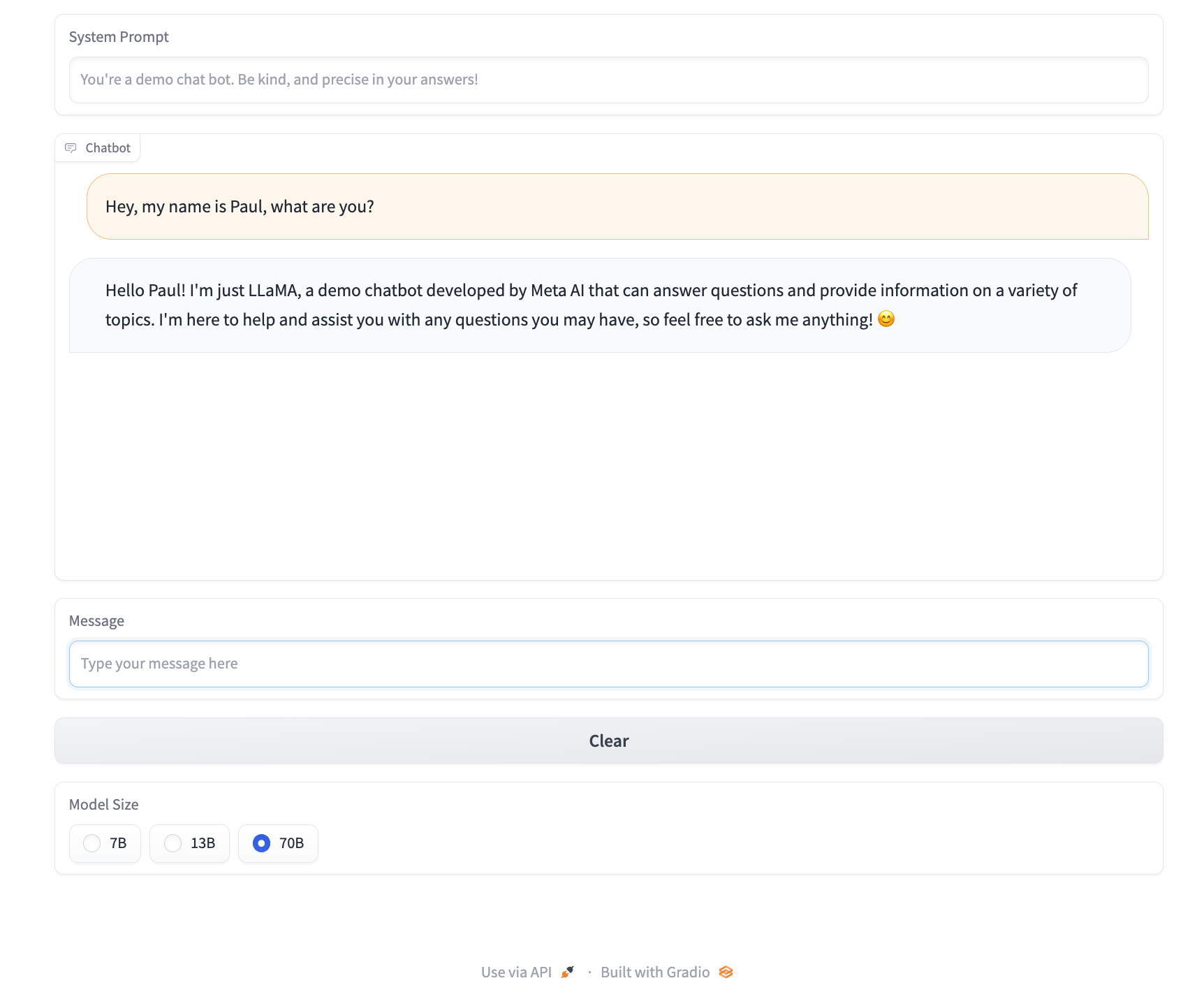
Full code
import gradio as gr
from pipeline.cloud.pipelines import run_pipeline
llama2_7b_pipeline = "meta/llama2-7B-chat:latest"
llama2_13b_pipeline = "meta/llama2-13B-chat:latest"
llama2_70b_pipeline = "meta/llama2-70B-chat:latest"
target_model = llama2_13b_pipeline
generation_kwargs = dict(
max_new_tokens=200,
)
system_prompt = """You're a demo chat bot. Be kind, and precise in your answers!"""
with gr.Blocks() as demo:
system_prompt_box = gr.Textbox(
label="System Prompt",
placeholder=system_prompt,
)
chatbot = gr.Chatbot()
msg = gr.Textbox(
label="Message",
placeholder="Type your message here",
)
clear = gr.ClearButton([msg, chatbot])
model_select = gr.Radio(choices=["7B", "13B", "70B"], label="Model Size")
def respond(message, chat_history):
_input = []
_input.append({"role": "system", "content": system_prompt})
for user_msg, bot_msg in chat_history:
_input.append({"role": "user", "content": user_msg})
_input.append({"role": "assistant", "content": bot_msg})
_input.append({"role": "user", "content": message})
output = run_pipeline(target_model, [_input], generation_kwargs)
new_message = output.result.result_array()[0][0]["content"]
chat_history.append((message, new_message))
return "", chat_history
def system_update(new_prompt):
global system_prompt
system_prompt = new_prompt
def model_select_fn(model):
global target_model
if model == "7B":
target_model = llama2_7b_pipeline
elif model == "13B":
target_model = llama2_13b_pipeline
elif model == "70B":
target_model = llama2_70b_pipeline
msg.submit(respond, [msg, chatbot], [msg, chatbot])
system_prompt_box.change(system_update, system_prompt_box)
model_select.change(model_select_fn, model_select)
demo.launch()
Updated over 2 years ago